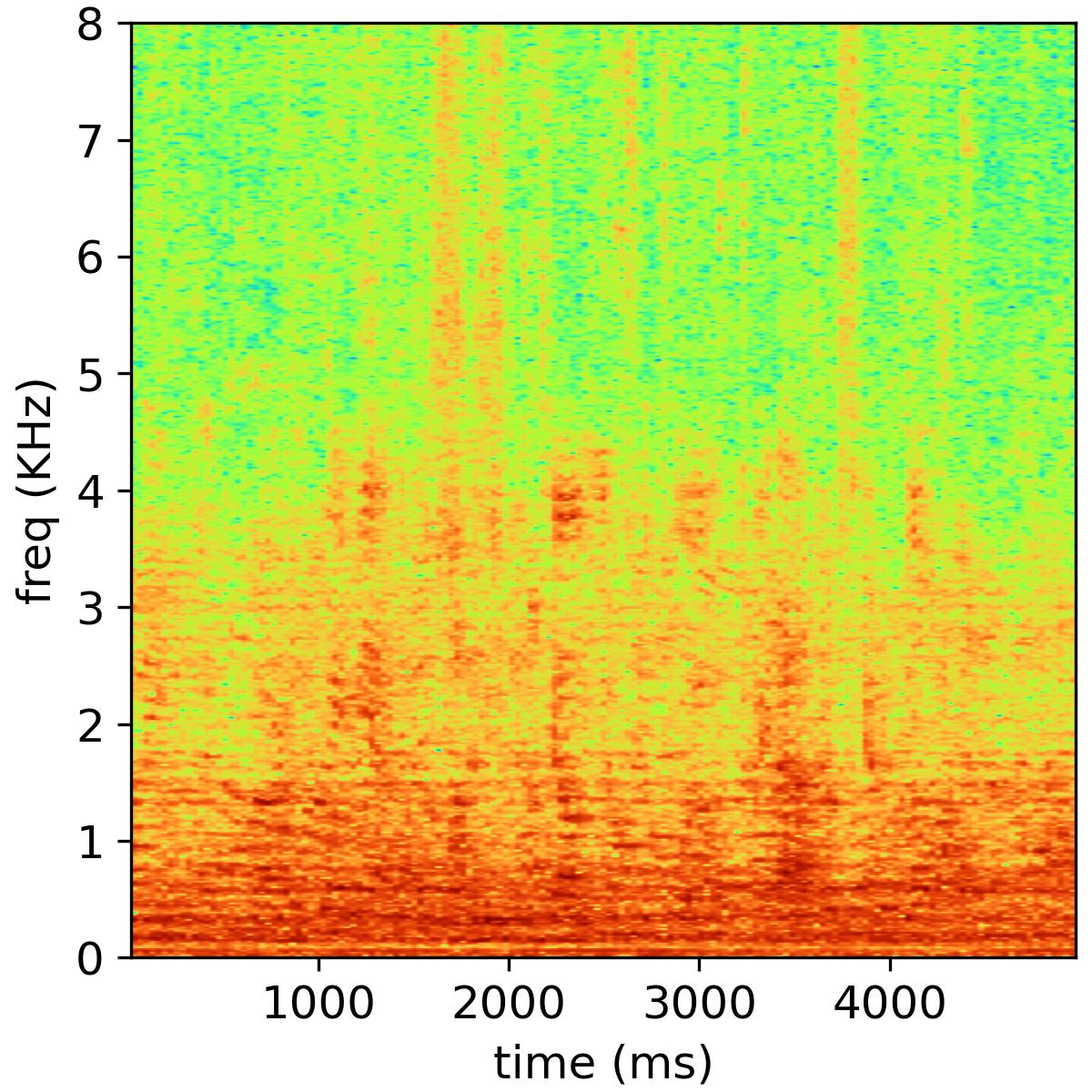
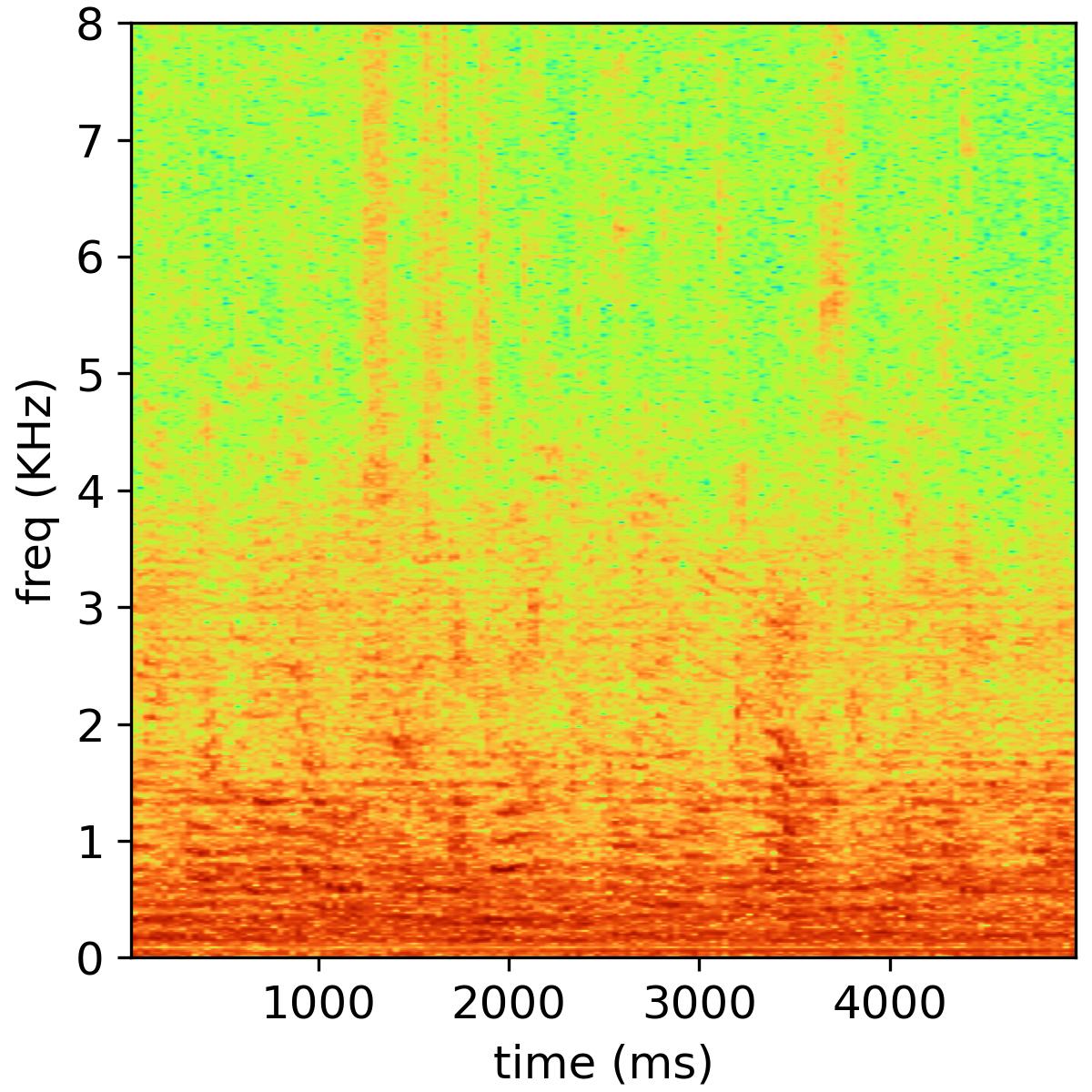
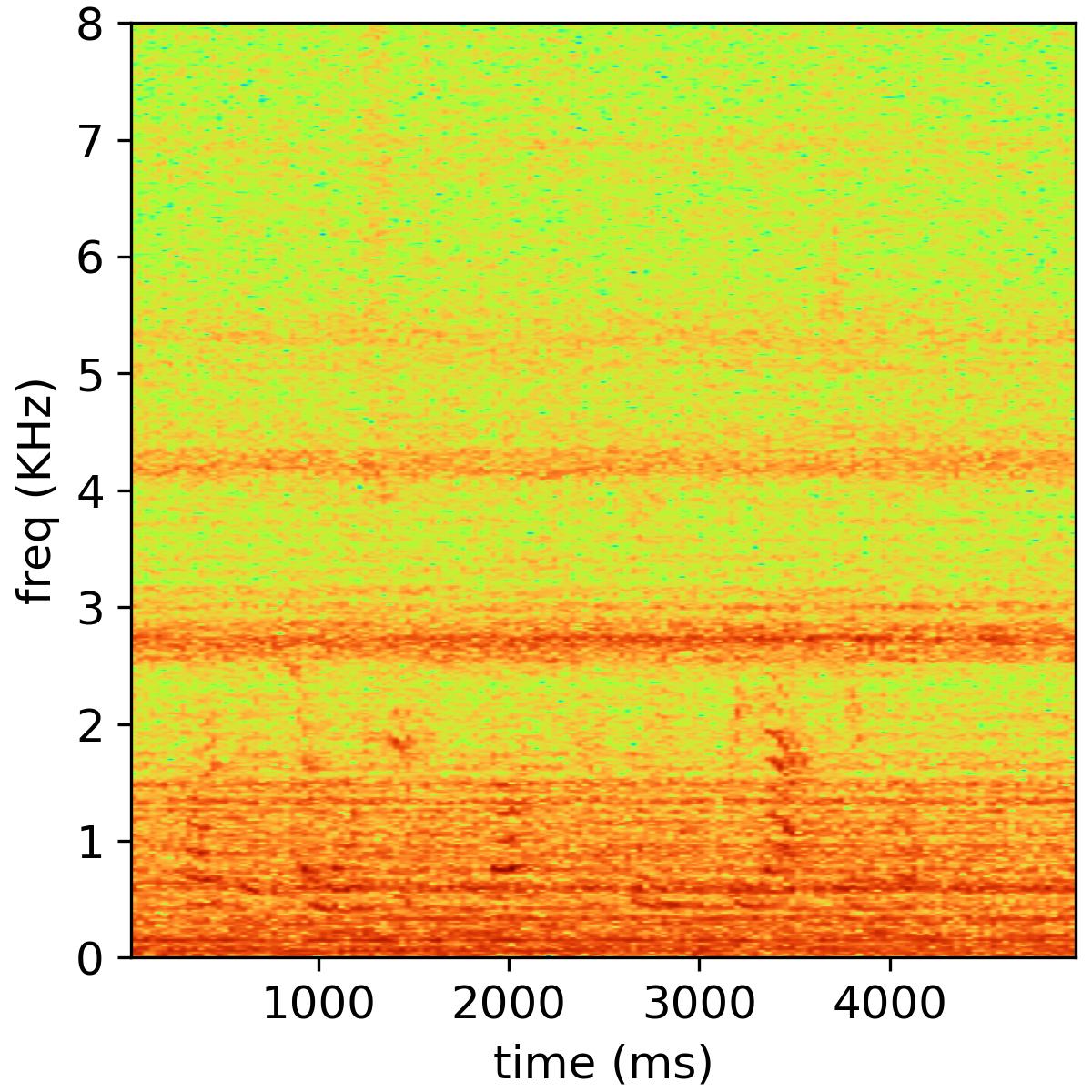
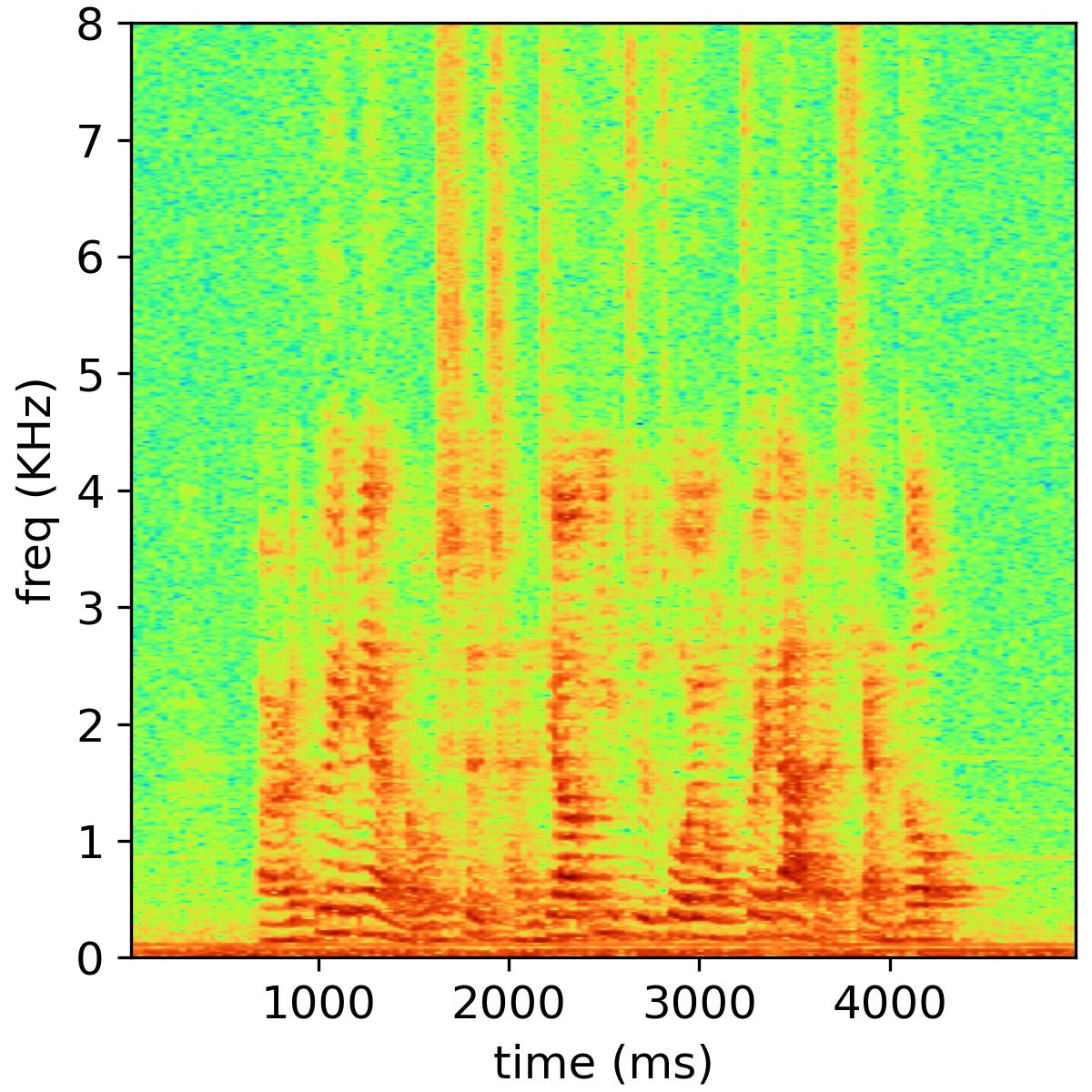
Audio & Speech Research Group is a research group under the Key Laboratory of Noise and Vibration Research, Institute of Acoustics, Chinese Academy of Sciences. The Principal Investigator of this research group is Prof. Feiran Yang (杨飞然). Our research interests include Adaptive Filtering, Blind Source Separation, Array Signal Processing, Voice Anti-Spoofing, Acoustic Echo Cancellation, Speech Enhancement. See HERE
The members of group includes Feiran Yang (杨飞然), Yi Wan (万伊), Taihui Wang (王泰辉), Shengdong Liu (刘升东), Zhengqiang Luo (罗正强), Yang Liu (刘杨), Jinfu Wang (王劲夫), Changtao Li (李长涛), Jing Lei (雷菁), Kelan Kuang (匡柯澜), Qing Shi(石擎), Lan Tang (汤澜), Cong Zhang(张聪), Haobo Jia (贾浩博), Dianzhe Ding (丁殿哲).
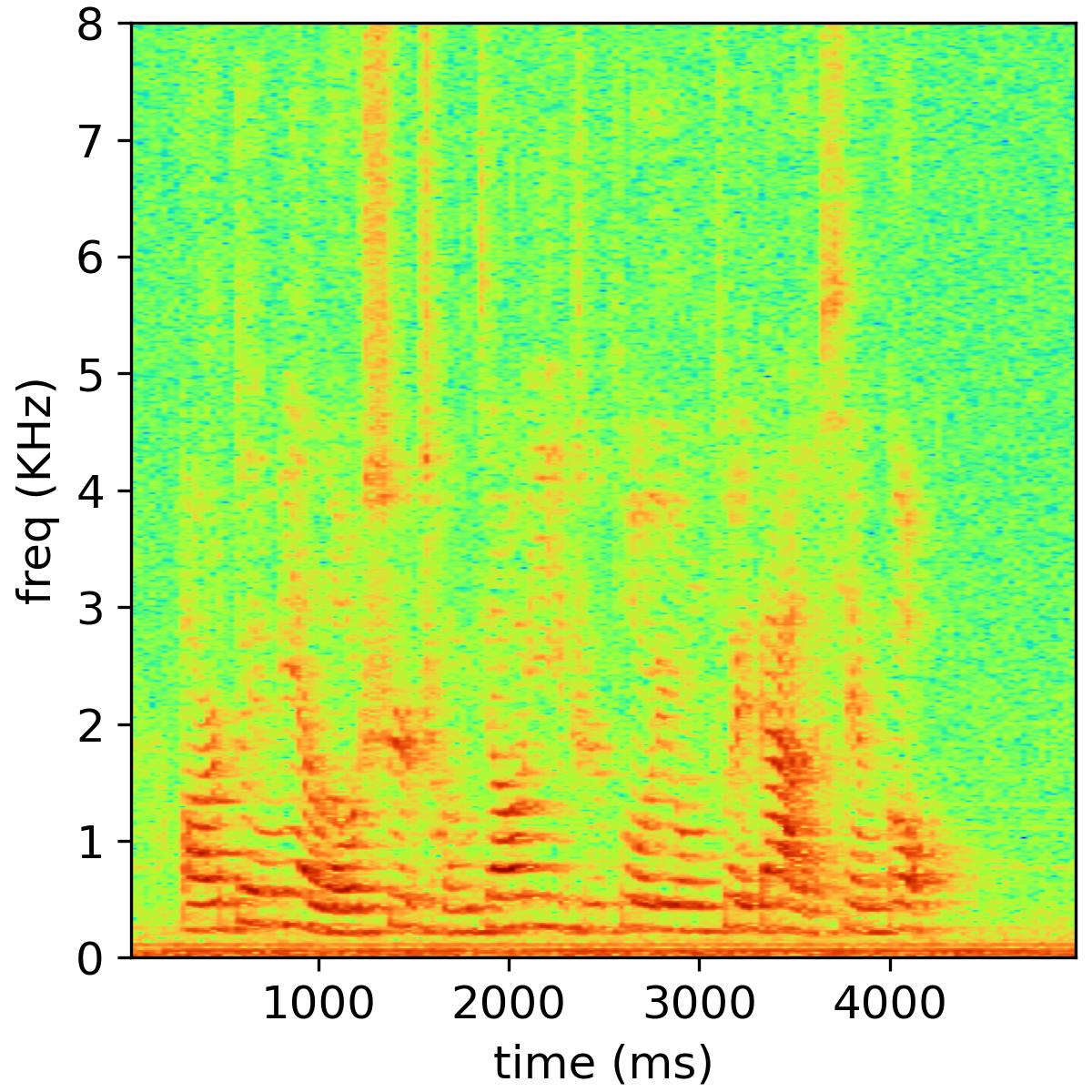
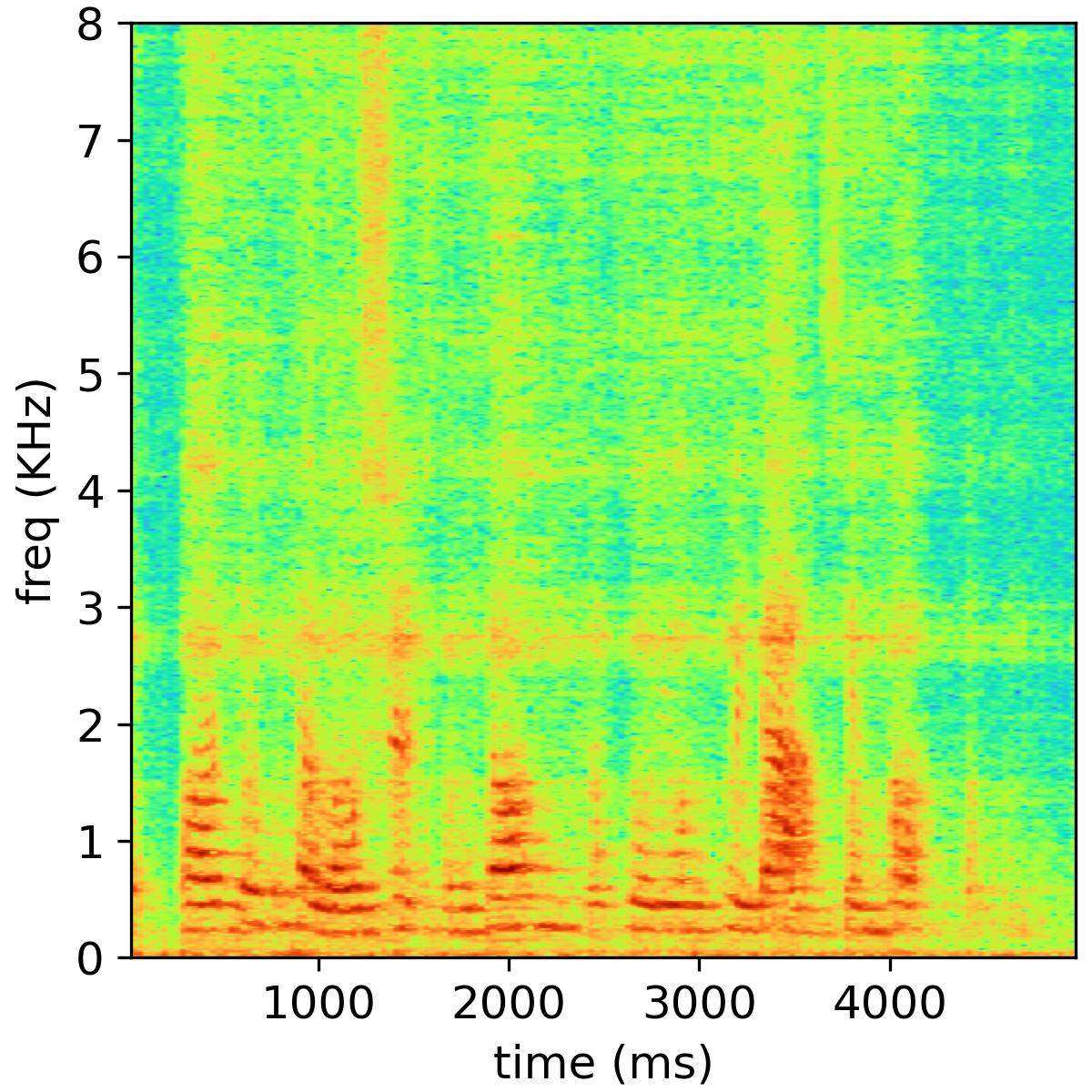
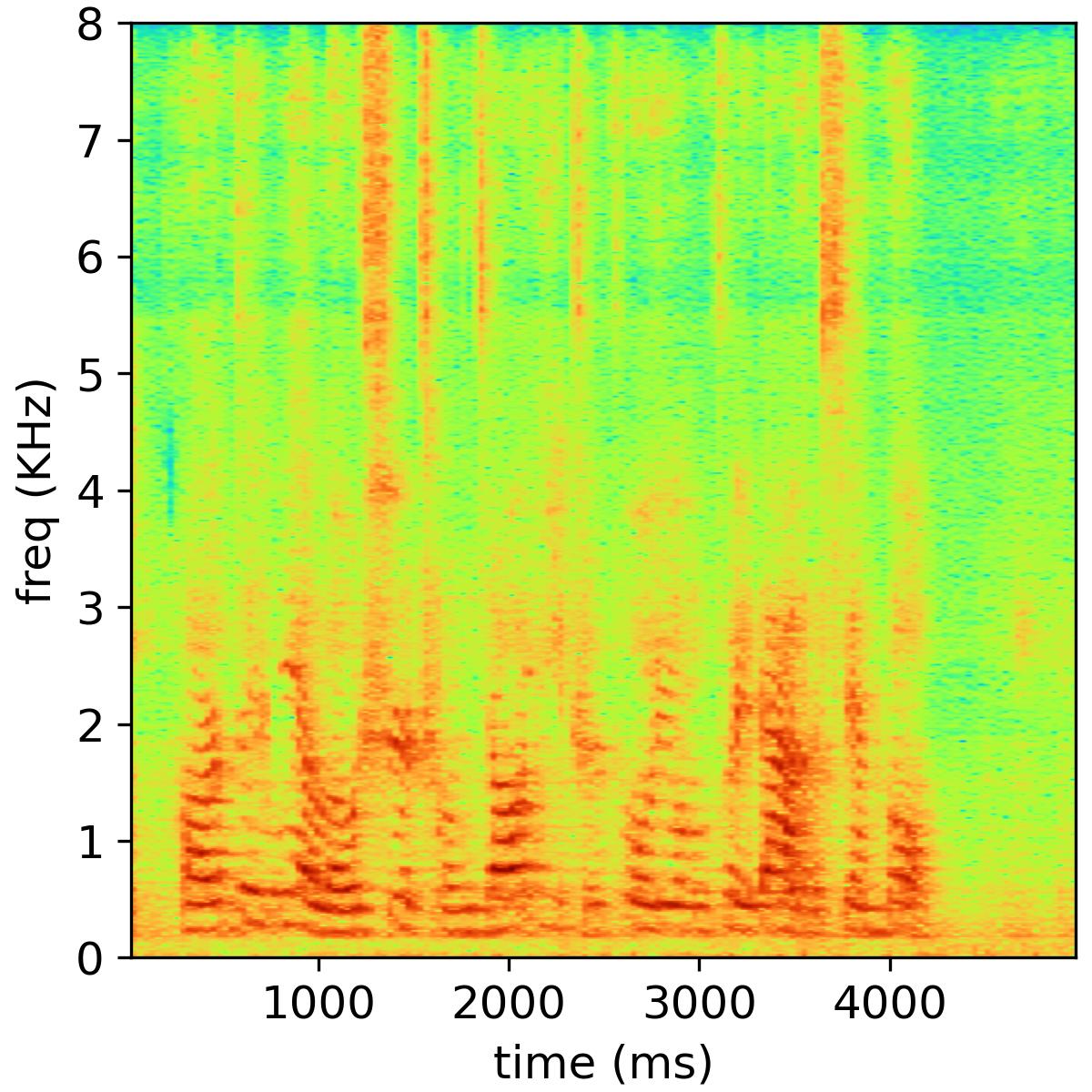
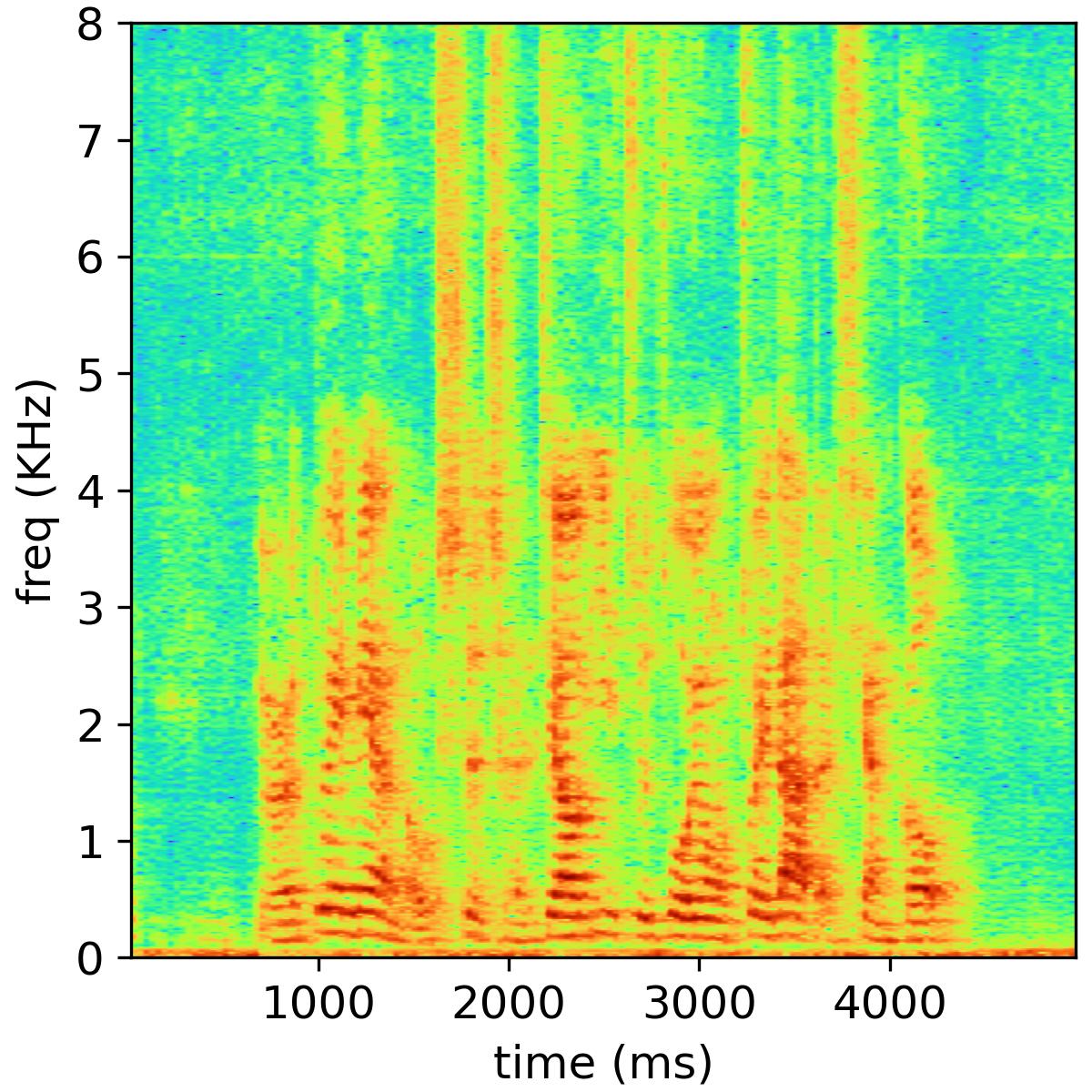
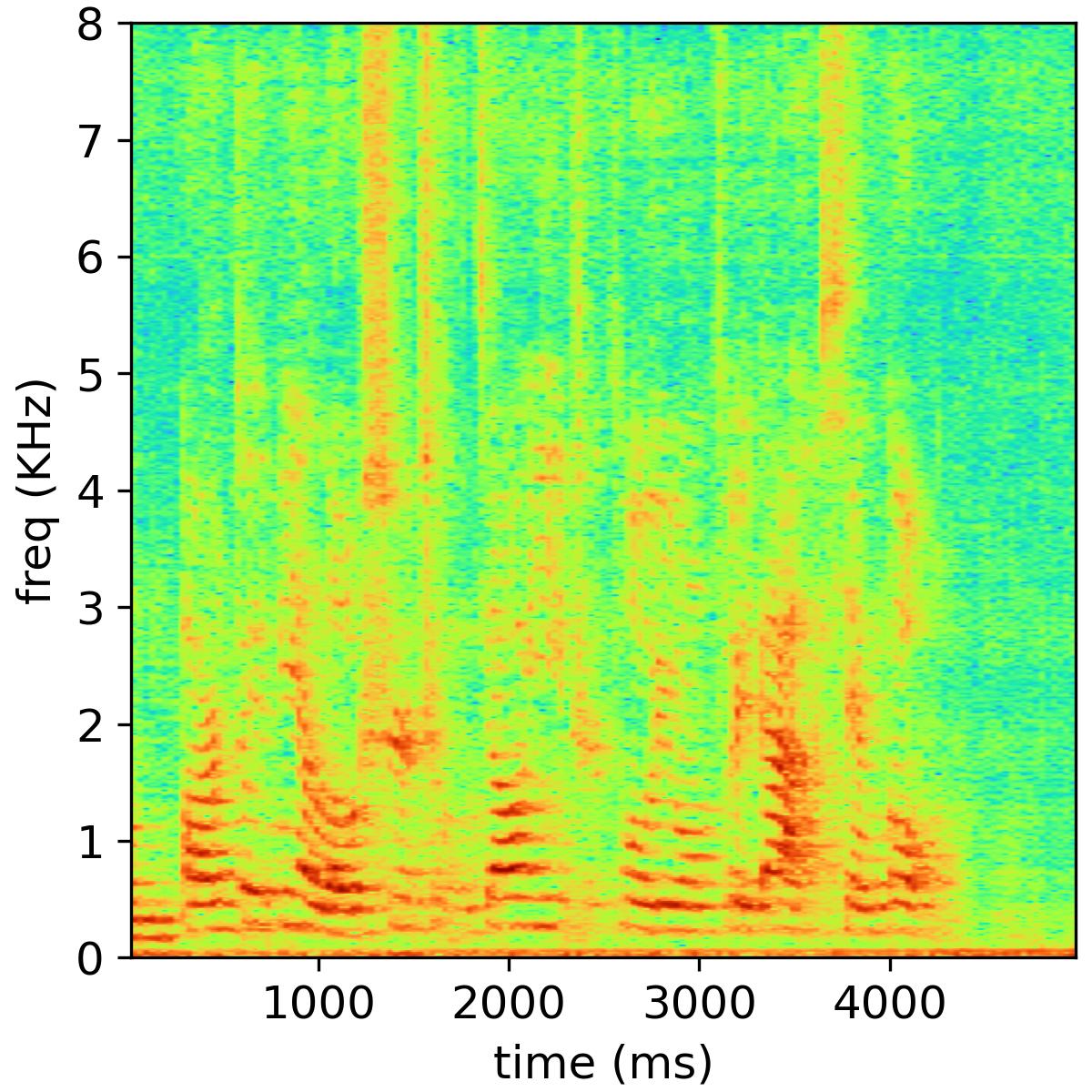
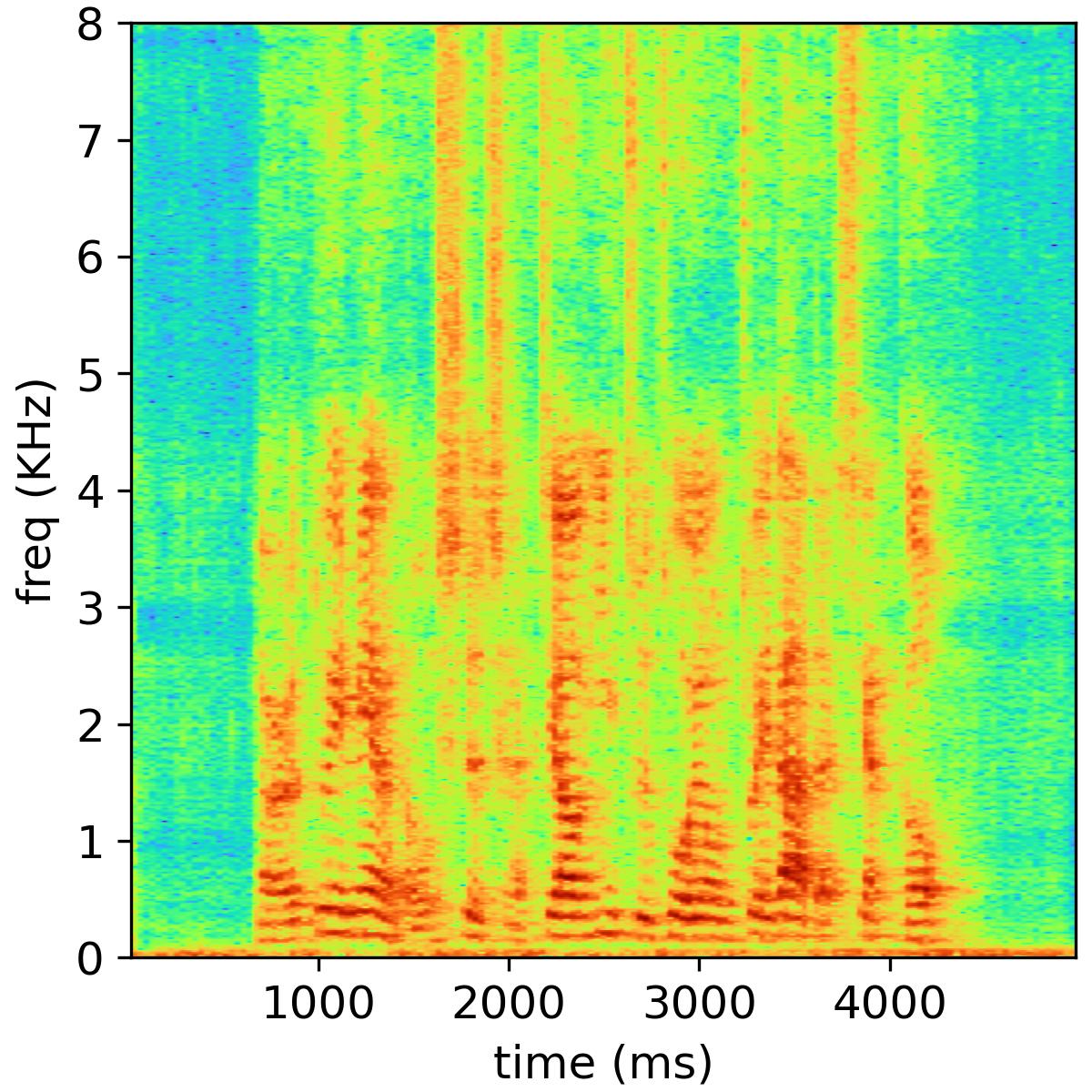
We present some speech samples in the website to show the dual-channel magnitude-phase learning with cross-attention for bone-conducted speech. Objective and subjective evaluations on A4BS dataset show that our system substantially outperforms existing bone-conducted speech enhancement systems.
Samples
We encourage our readers to listen to the following audio samples in order to experience the audio quality of our enhanced speech. Due to the large number of audio files, the loading time might be prolonged. Kindly wait for a moment or consider closing other web pages and refreshing the website to improve the loading speed.
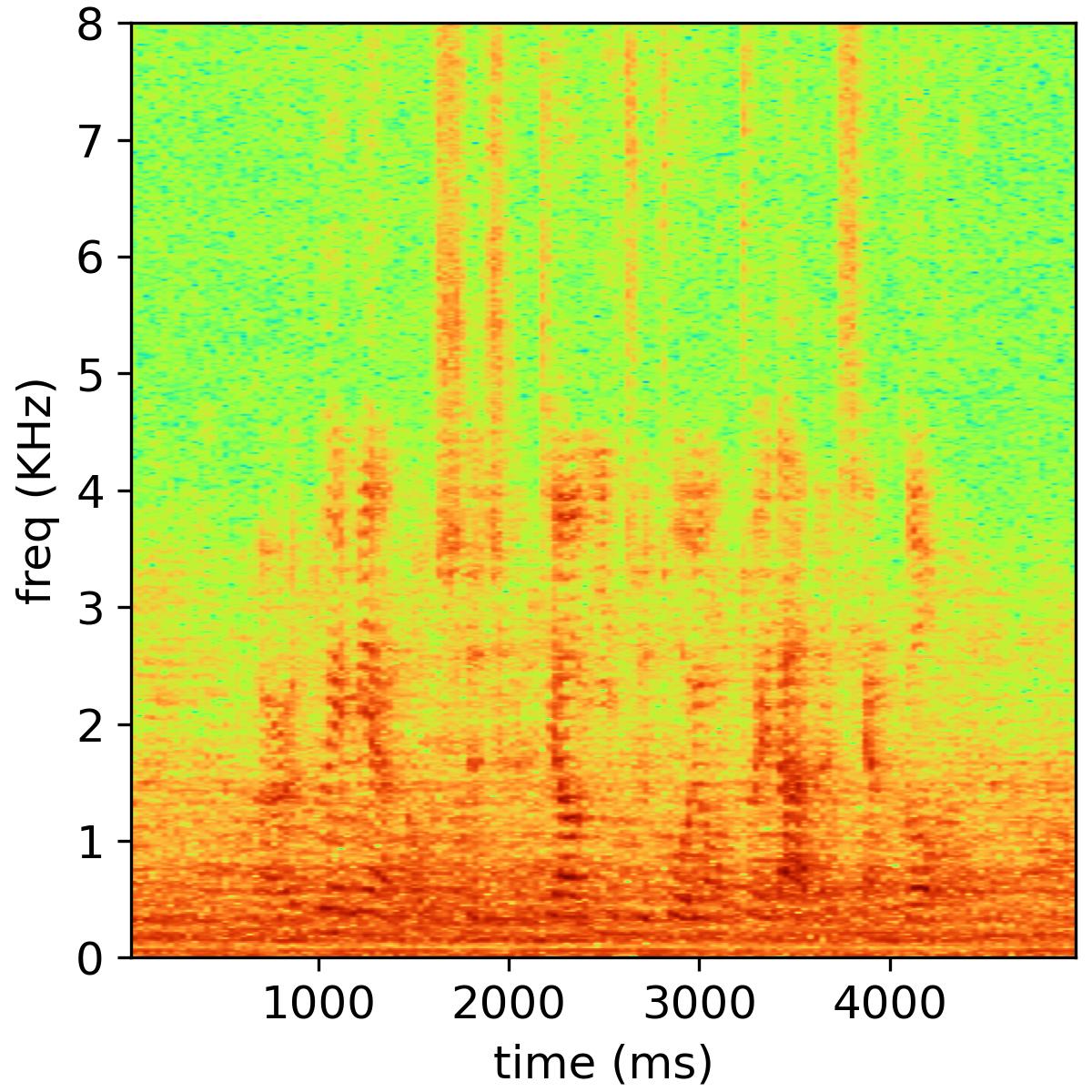
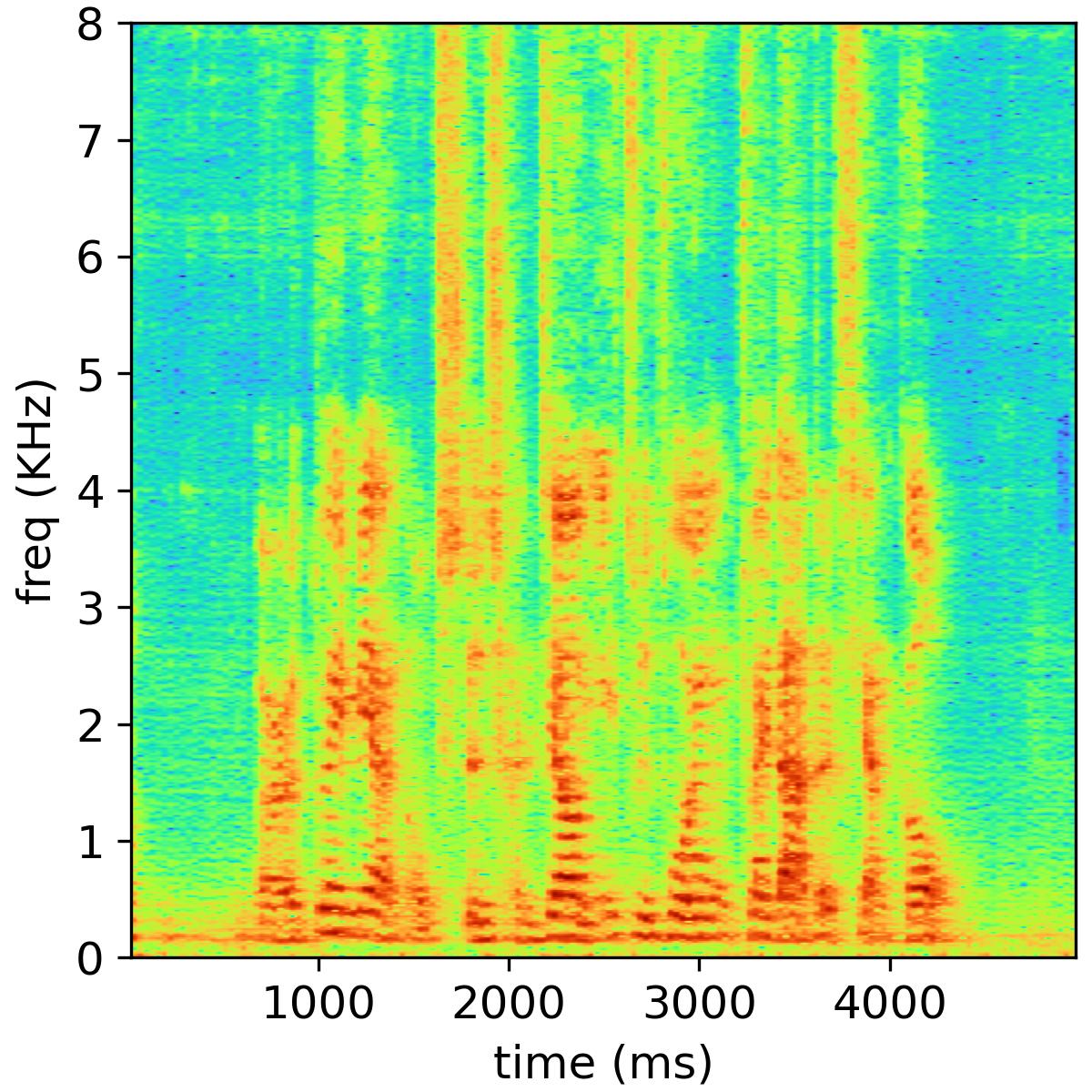
This paper investigates the joint use of bone-conducted and air-conducted speech in a multimodal speech enhancement framework. Starting from the backbone network architecture, we design a temporal two-tower network named after BiNet, capable of directly processing both bone-conducted and noisy air-conducted speech inputs. BiNet employs two independent encoders to map bone-conducted and noisy air-conducted speech into a shared embedding space. A decoder is then utilized to reconstruct the target clean speech from the embedding features of both modalities. Additionally, skip connections are incorporated in BiNet to better capture the long-term and short-term temporal correlations in speech. Considering the significance of spectral components in speech perception, we adopt a multi-scale mel-spectrogram loss function as the training objective, which encourages the network to generate more plausible spectral details of the desired speech. The aforementioned backbone network design allows us to apply regularization constraints based on contrastive learning. By controlling the similarity between the embedding features of bone-conducted and noisy air-conducted speech, we impose two regularization constraints on BiNet. When the embedding features of these two modalities exhibit higher similarity, the proposed BiNet achieves superior speech enhancement performance. Extensive experiments conducted on a recorded dataset of bone-conducted/air-conducted speech validate our approach. By combining the proposed model with contrastive learning regularization constraints, our method outperforms baseline models and several recent multimodal speech enhancement systems in terms of PESQ and STOI metrics.
Samples
We encourage our readers to listen to the following audio samples in order to experience the audio quality of our enhanced speech.
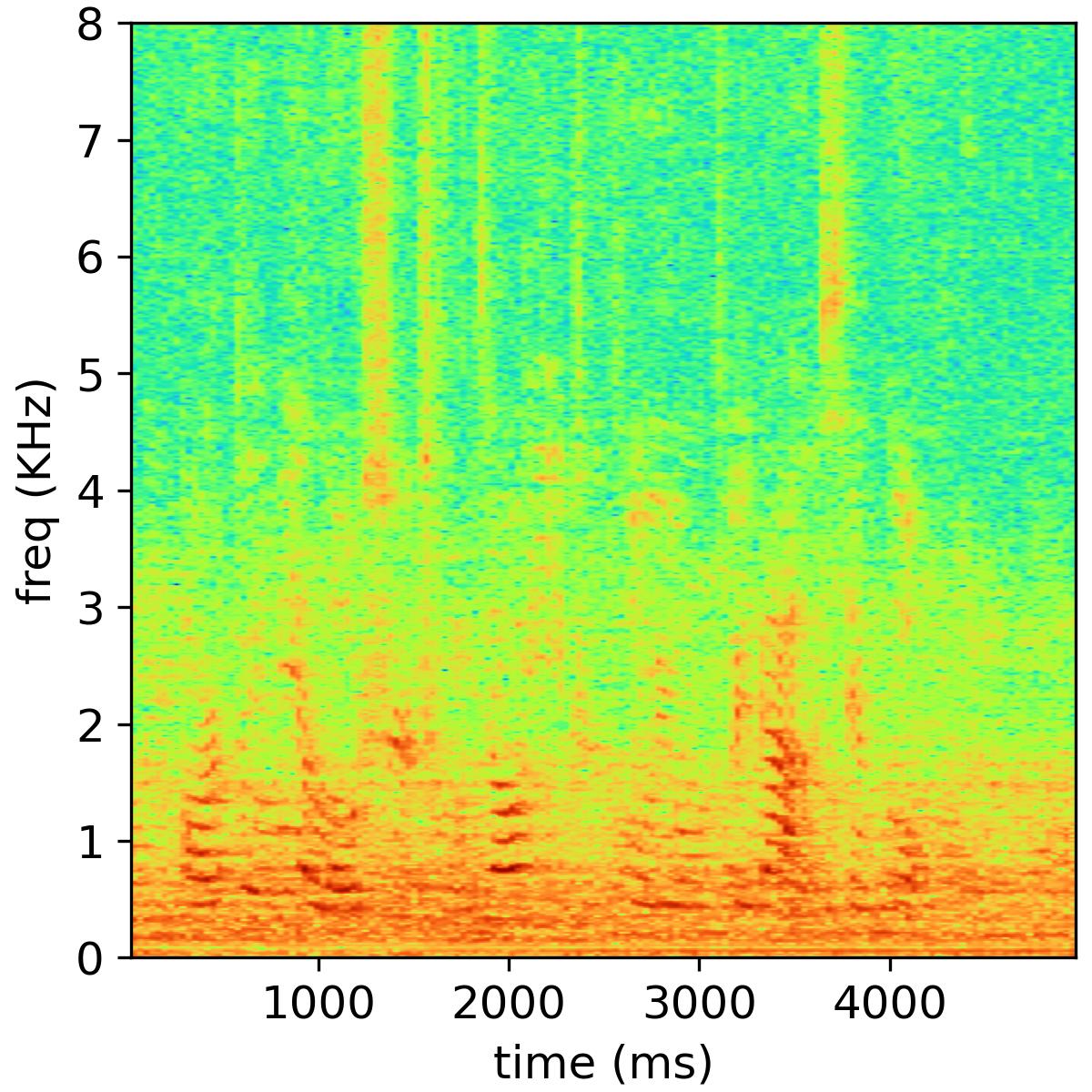
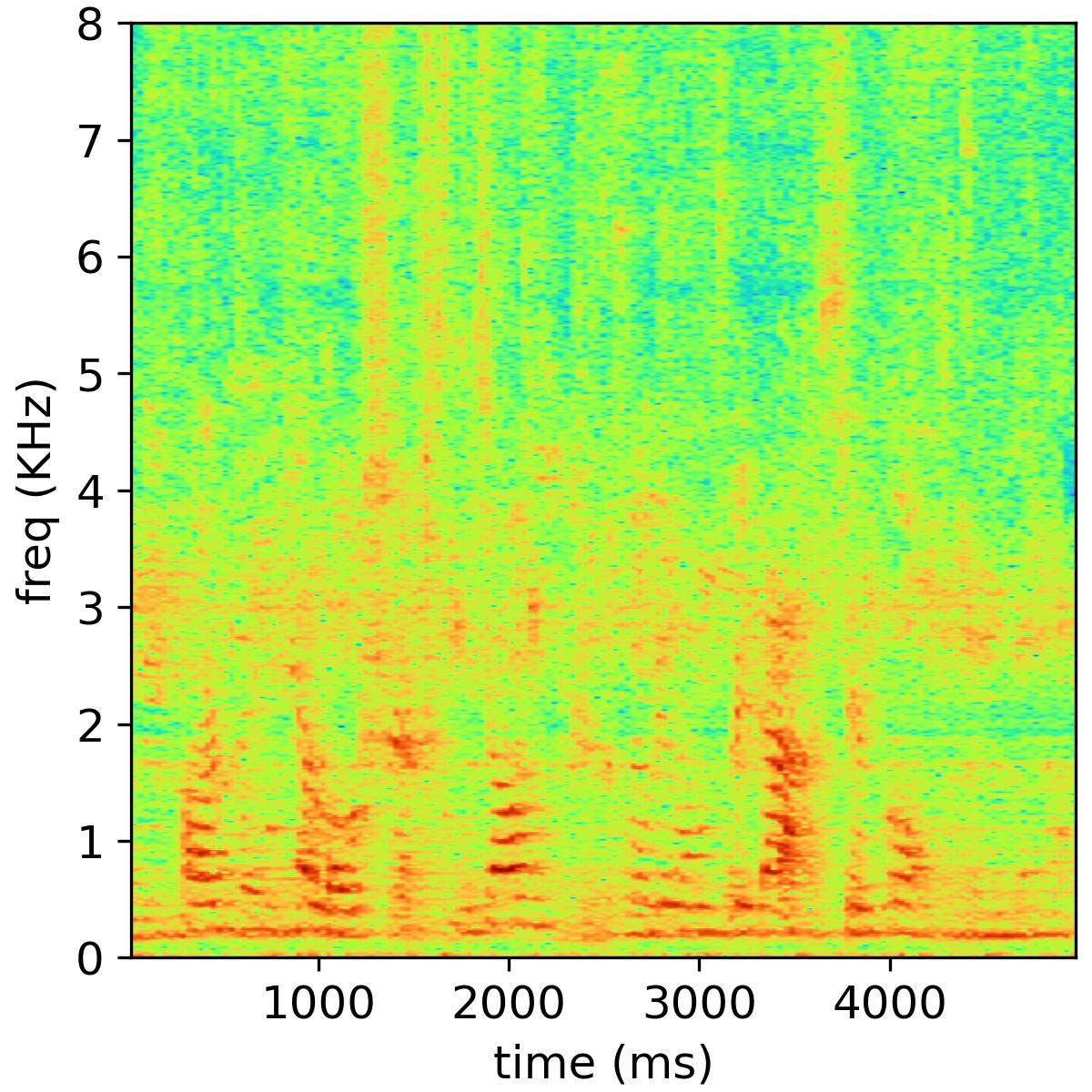
Bone-conducted speech is not susceptible to background noise but suffers from poor speech quality and intelligibility due to the limited bandwidth. This paper proposes a two-stage approach to restore the quality of bone-conducted speech, namely, bandwidth extension and speech vocoder. In the first stage, a deep neural network is trained to learn mappings from a low-resolution representation of the bone-conducted speech, i.e., log Mel-scale spectrogram, to that of the air-conducted speech, which extends the bandwidth of the bone-conducted speech. In the second stage, a speech vocoder is employed to transform the extended log Mel-scale spectrogram of the bone-conducted speech back to time-domain waveforms. Due to the many-to-many correspondence between the air-conducted and bone-conducted speech, supervised learning may not be the best training protocol for the bone-conducted/air-conducted feature mapping. We thus propose to leverage adversarial training to further improve the bandwidth extension performance in the first stage. The two stages are decoupled and can be trained independently. The vocoder is trained on a large multi-speaker dataset and can generalize well to unknown speakers. Also, the vocoder can help to remedy the spectral artifacts introduced in the bandwidth extension stage. Objective and subjective evaluations on ESMB dataset show that the proposed two-stage system substantially outperforms existing bone-conducted speech enhancement systems.
Samples
We encourage our readers to listen to the following audio samples in order to experience the audio quality of our enhanced speech. Due to the large number of audio files, the loading time might be prolonged. Kindly wait for a moment or consider closing other web pages and refreshing the website to improve the loading speed.
Convolutive Transfer Function-Based Multichannel Nonnegative Matrix Factorization for Overdetermined Blind Source Separation
Taihui Wang 1, 2 , Feiran Yang 3 , Member, IEEE, and Jun Yang 1, 2 , Senior Member, IEEE
1 Key Laboratory of Noise and Vibration Research, Institute of Acoustics, Chinese Academy of Sciences, Beijing, China
2 University of Chinese Academy of Sciences, Beijing, China
3 State Key Laboratory of Acoustics, Institute of Acoustics, Chinese Academy of Sciences, Beijing, China
Abstract
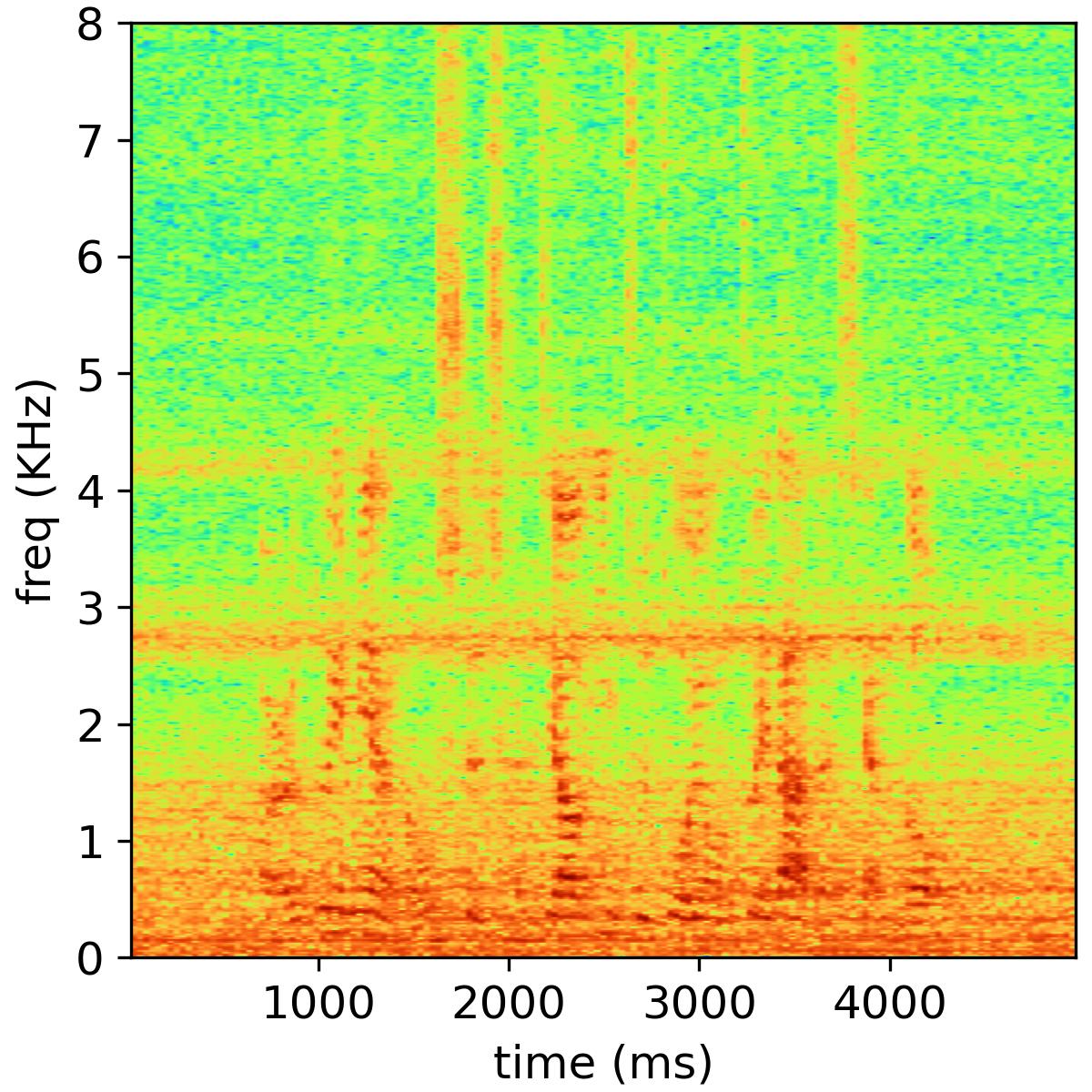
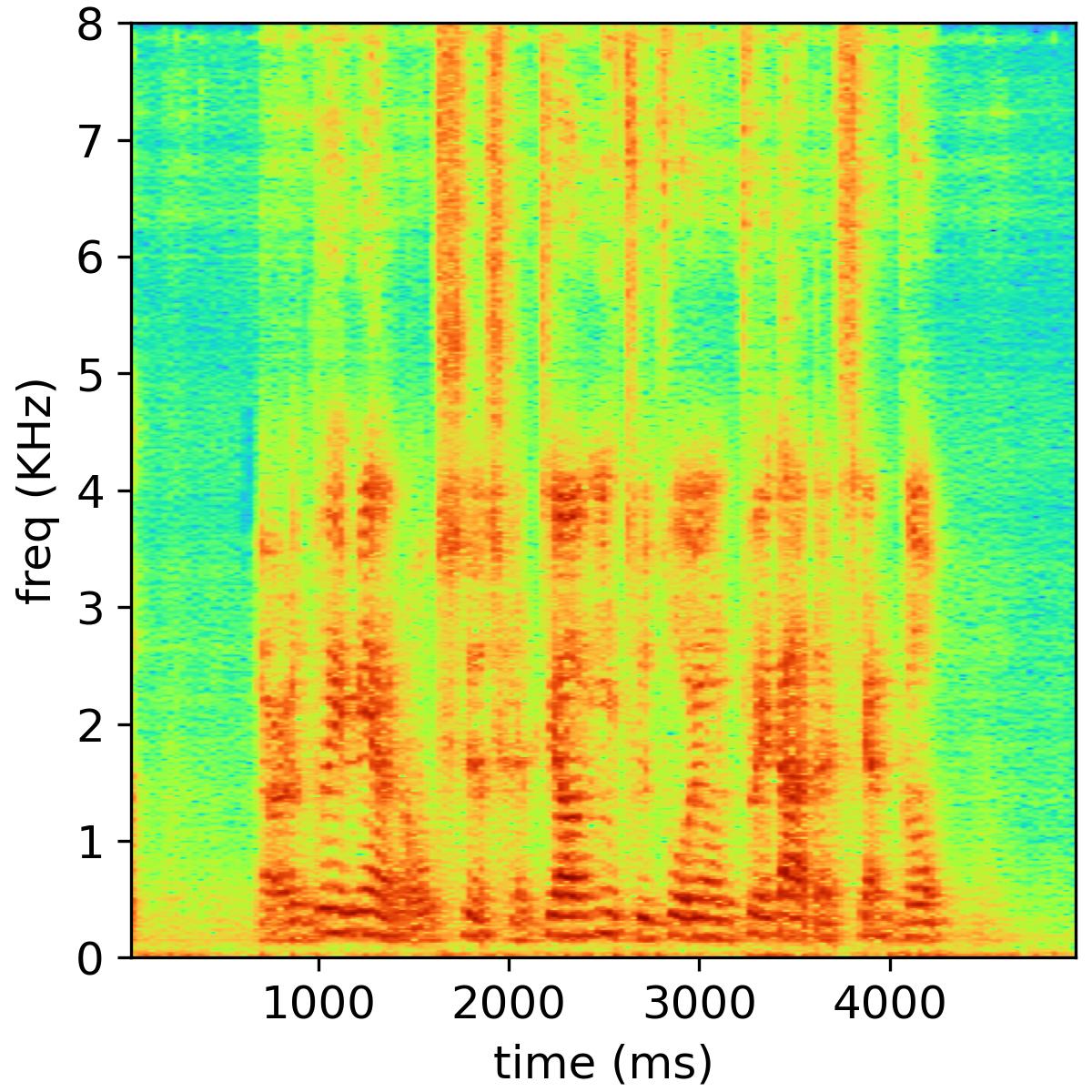
Most multichannel blind source separation (BSS) approaches rely on a spatial model to encode the transfer functions from sources to microphones and a source model to encode the source power spectral density. The rank-1 spatial model has been widely exploited in independent component analysis (ICA), independent vector analysis (IVA), and independent low-rank matrix analysis (ILRMA). The full-rank spatial model is also considered in many BSS approaches, such as full-rank spatial covariance matrix analysis (FCA), multichannel nonnegative matrix factorization (MNMF), and FastMNMF, which can improve the separation performance in the case of long reverberation times. This paper proposes a new MNMF framework based on the convolutive transfer function (CTF) for overdetermined BSS. The time-domain convolutive mixture model is approximated by a frequency-wise convolutive mixture model instead of the widely adopted frequency-wise instantaneous mixture model. The iterative projection algorithm is adopted to estimate the demixing matrix, and the multiplicative update rule is employed to estimate nonnegative matrix factorization (NMF) parameters. Finally, the source image is reconstructed using a multichannel Wiener filter. The advantages of the proposed method are twofold. First, the CTF approximation enables us to use a short window to represent long impulse responses. Second, the full-rank spatial model can be derived based on the CTF approximation and slowly time-variant source variances, and close relationships between the proposed method and ILRMA, FCA, MNMF and FastMNMF are revealed. Extensive experiments show that the proposed algorithm achieves a higher separation performance than ILRMA and FastMNMF in reverberant environments.
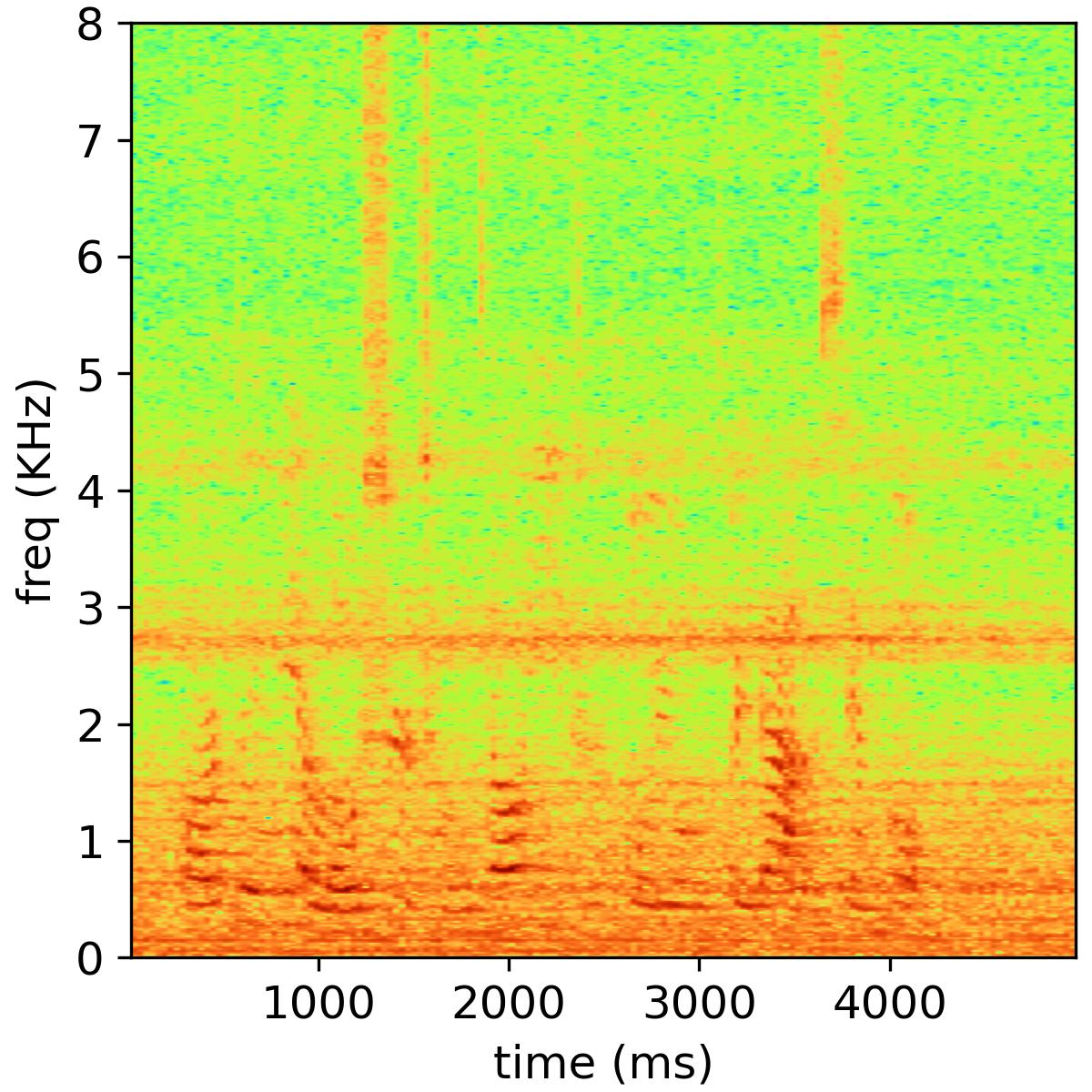
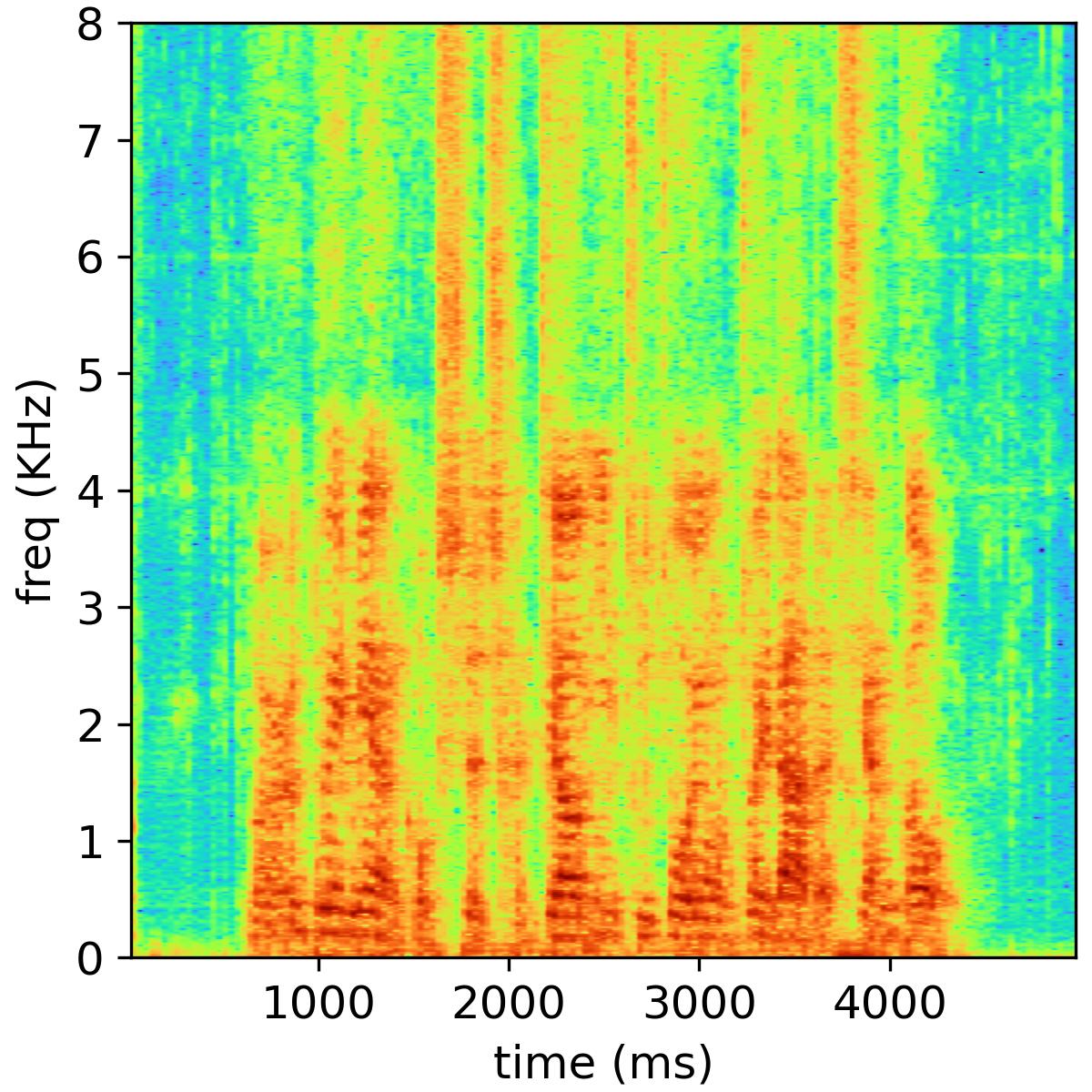
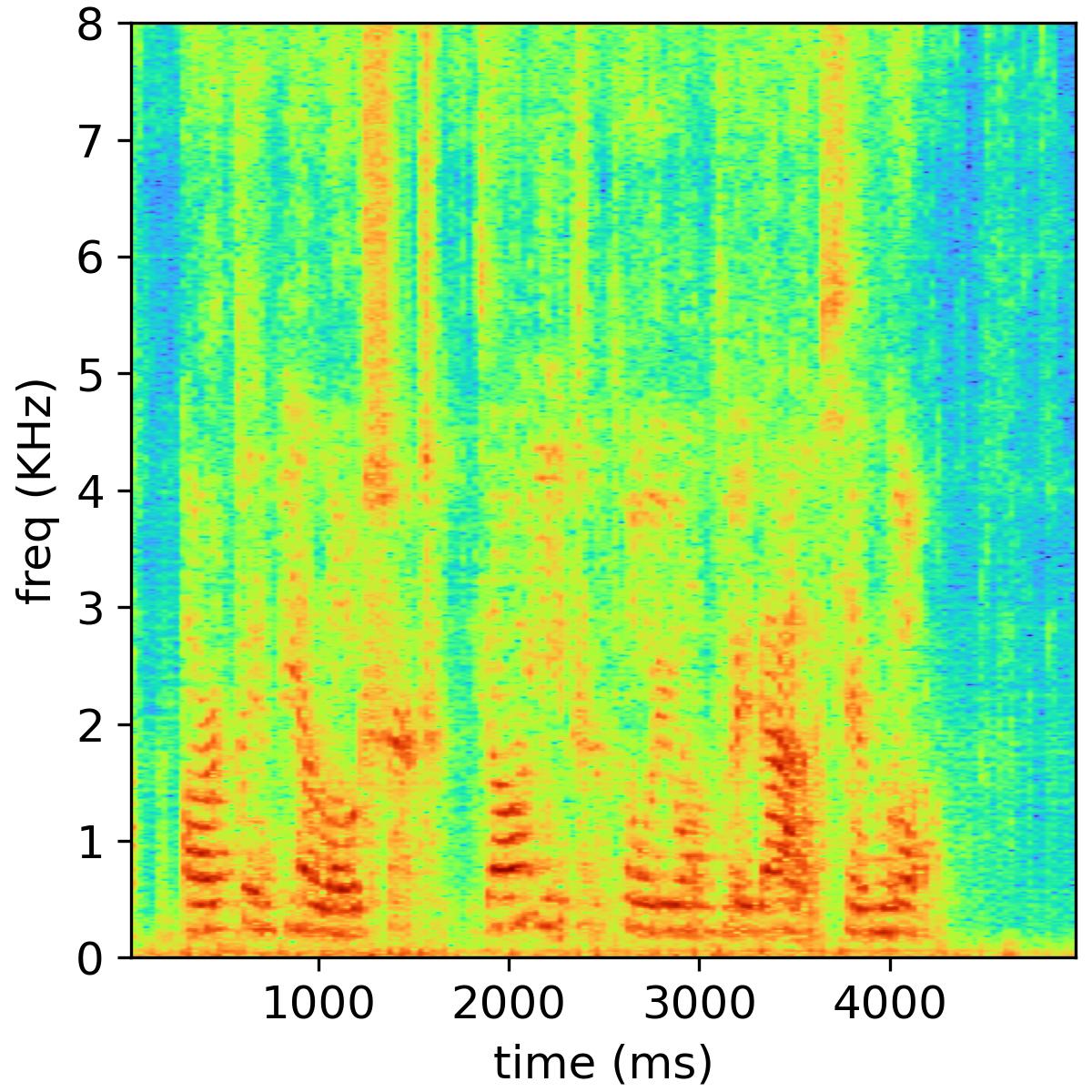
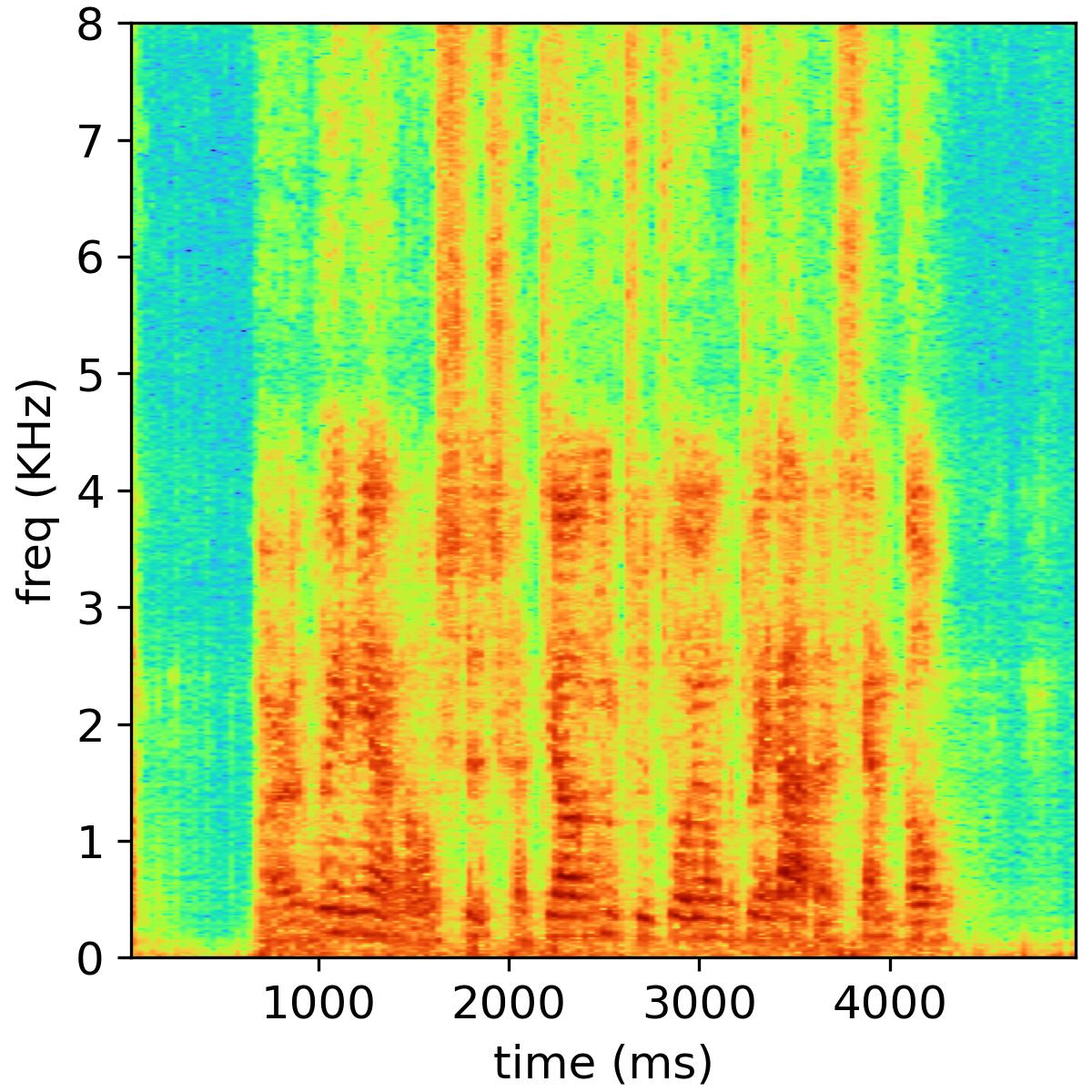
Separated audio samples
The following table shows an example of the 2-music source separation task, where the public NMF model is used and the number of bases is set to 32. The reverberation time is 470 ms, and the channel number is 6.